U-Netの逆畳み込み・転置畳み込み(Unpooling・Transposed Convolution)がわかりません。
1[マトラボのセマンティック説明]
https://jp.mathworks.com/content/dam/mathworks/mathworks-dot-com/company/events/webinar-cta/2459280_Basics_of_semantic_segmentation.pdf
ーーーーーーーーーー
{kind=link}
上記文献1の20ページにSegNetのUnpoolingの図があります。これは画像特徴をエンコードする前に取得し、逆プーリングを施す際にMaxプーリングしたところにそれを代入するとのこと。
一方、34ページにU-netの転置畳み込みがstride2×2で行われている事が書かれています。ここで
104^2の行列が深度連結?で512個になっているところから、一回3×3,stride1の畳み込みを経る事で102^2の行列が256個になっています。
質問(1)
なぜ512が256になっているのでしょうか?これはSegNetにおけるUnpoolingのようにMaxpoolingで使用したピクセルを保存しておいて、そこに代入しているのでしょうか?ただ、それなら転置畳み込みの段階で256個になっていると思うのですが…よくわかっていません。
質問(2)
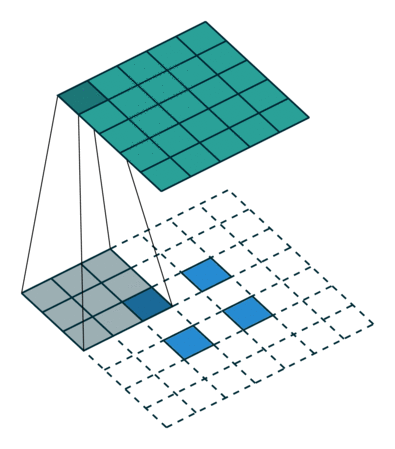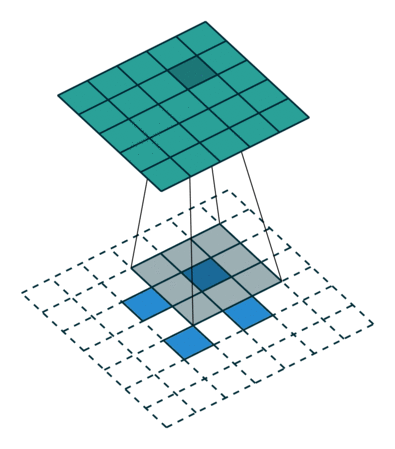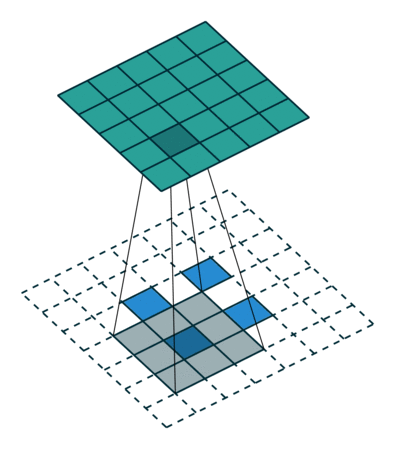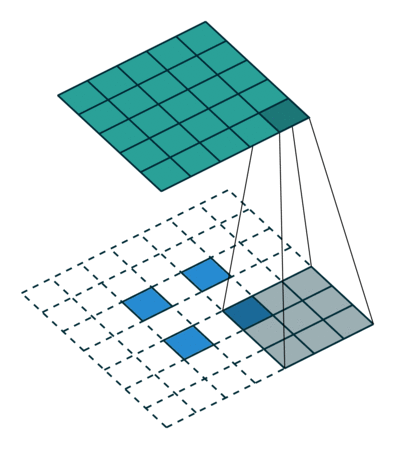
転置畳み込みと、SegNetで使われているUnpoolingは両方とも画像拡大に使われているようですが、この二つの処理は全く異なる物であっていますでしょうか?U-NetではUnpoolingは使われていないのでしょうか?もしそうなら、転置畳み込みの段階で
https://cdn-images-1.medium.com/max/960/1*Lpn4nag_KRMfGkx1k6bV-g.gif
(元サイト https://towardsdatascience.com/types-of-convolutions-in-deep-learning-717013397f4d)
のように拡大してくのではと考えているのですが、U-Netではどのように空間をとって拡大処理をしているのでしょうか?(上記の例では周りに2ピクセル分の外周をくっつけて、更に元の2×2の中に1ピクセルを十字型に仕込んでいますが…)
以上2点についてお願いいたします。